Motivation: Why Prosto?¶
Why functions and column-orientation?¶
In traditional approaches to data processing, we frequently need to produce a new table even though we need to define a new attribute. For example, in SQL, a new relation has to be produced even if we want to define a new calculated attribute. We also need to produce a new relation (using join) if we want to add a column with data from another table. Data aggregation by means of groupby operation produces a new relation too, although the goal is to compute a new attribute.
In many important cases, processing data using only set operations is counter-intuitive, and this is why map-reduce, join-groupby (including SQL) and similar set-oriented approaches require high expertise and are error-prone
The main unique novel feature of Prosto is that it relies on a different formal basis:
Prostoadds mathematical functions (implemented as columns) to its model by significantly simplifying data processing and analysis
Now, if we want to define a new attribute then we can do it directly without defining new unnecessary tables, collections or relations. New columns are defined in terms of other columns (in different tables) and this makes this model similar to how spreadsheets work but instead of cells we use columns. For comparison, if in spreadsheets we could define a new cell as A1=B2+C3, then in Prosto we could define a new column as Column1=Column2+Column3. The main theoretical challange is in introducing a set of column operations between columns in multiple tables in such a way that these operations effectively replace relational operations (join and groupby) and cover most important use cases. How it is done is described in [2]. Prosto with Column-SQL is one possible implementation of this model.
Below we describe three use cases where applying set operations is an unnecessary and counter-intuitive step. The example data model shown in this diagram is used for demonstration purposes. (Note however that it does not exactly corresponds to the use cases.)
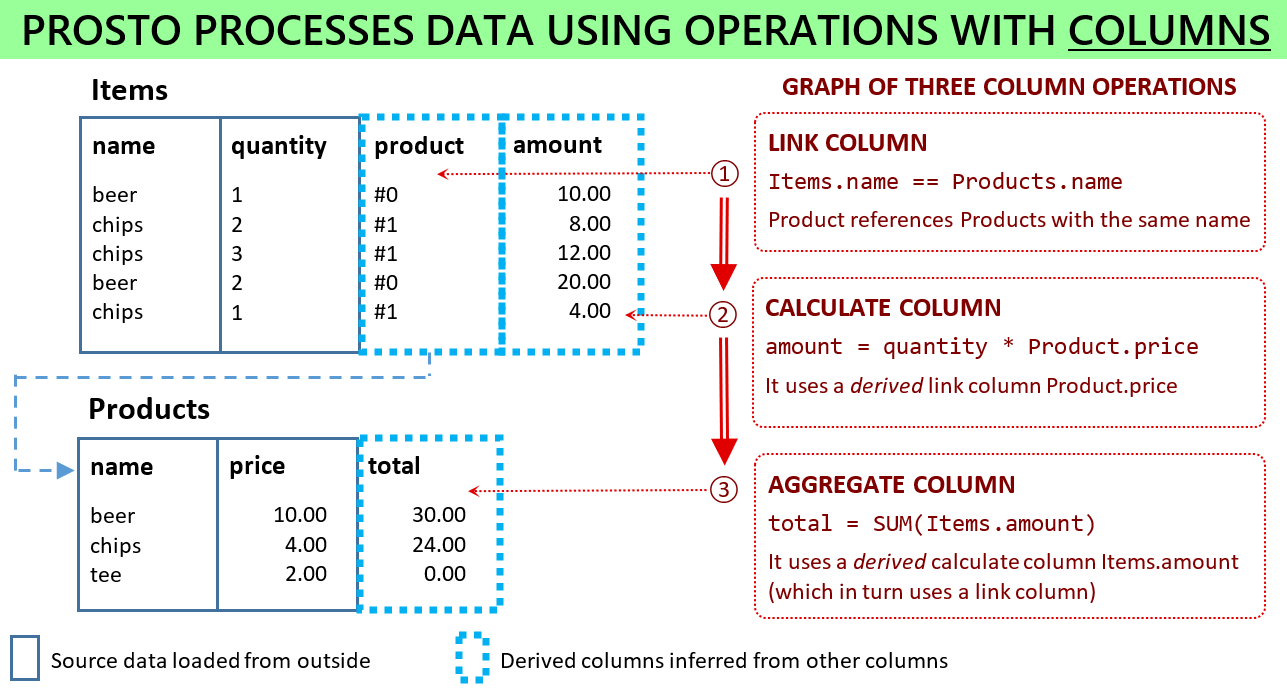 Data processing workflow
Data processing workflow
Calculating data¶
One of the simplest operations in data processing is computing a new attribute using already existing attributes. For example, if we have a table Items containing orders characterized by quantity and price then we could compute a new attribute amount as their arithmetic product:
SELECT *, quantity * price AS amount FROM Items
This wide spread data processing pattern may seem very natural and almost trivial but it actually has one significant conceptual flaw:
the task was to compute a new attribute while the query produces a new table
Although the result table does contain the required attribute, the question is why not to do exactly what has been requested? Why is it necessary to produce a new table if we actually want to compute only an attribute?
The same problem exists in map-reduce. If our goal is to compute a new field then we apply the map operation which will emit completely new collection of objects having this new field. Here again the same problem: our intention was not to create a new collection with new objects – we wanted to add a new computed property to already existing objects. However, the data processing framework forces us to describe this task in terms of operations with collections. We simply do not have any choice because such data models provide only sets and set operations, and the only way to add a new attribute is to produce a new set with this attribute.
An alternative approach consists in using column operations for data transformations so that we can do exactly what is requested: adding (calculated) attributes to existing tables.
Linking data¶
Another wide spread task consists in computing links or references between different tables: given an element of one table, how can I access attributes in a related table? For example, assume that price is not an attribute of the Items table as in the above example but rather it is an attribute of a Products table. Here we have two tables, Items and Products, each having name attribute which relates their records. If now we want to compute the amount for each item then the price needs to be retrieved from the related Products table. The standard solution is to copy the necessary attributes into a new table by using the relational (left) join operation for matching the records:
SELECT item.*, product.price FROM Items item
JOIN Products product ON item.name = product.name
This new result table can be now used for computing the amount precisely as we described earlier because it has the necessary attributes copied from the two source tables. Let us again compare this solution with the problem formulation. Do we really need a new table? No. Our goal was to have a possibility to access attributes from the second Products table (while computing a new attribute in the first table). Hence this again can be viewed as a workaround rather than a solution:
a new set is not needed for the solution and it is produced just because there is no possibility not to produce it
A principled solution to this problem would be a data model which uses column operations for data processing so that a link can be defined as a new column in an existing table.
Aggregating data¶
Assume that for each product, we want to compute the total number of items ordered. This task can be solved using group-by operation:
SELECT name, COUNT(name) AS totalQuantity
FROM Items GROUP BY name
Here again we see the same problem:
a new unnecessary table is produced although the goal is to produce a new (aggregated) attribute in an existing table
Indeed, what we really want is to add a new attribute to the Products table which would be equivalent to all other attributes (like product price used in the previous example). This totalQuantity could be then used to compute some other properties of products. Of course, this also can be done using set operations in SQL but then we will have to again use join to combine the group-by result with the original Products table followed by producing yet another table with new calculated attributes. It is apparently not how it should work in a good data model because the task formulation does not mention and does not actually require any new tables - only attributes. Thus we see that the use of set operations in this and above cases is a problem-solution mismatch.
A solution to this problem again would be a column oriented data model where aggregated columns could be defined without adding new tables.
Benefits of Prosto¶
Easily processing data in multiple tables¶
New derived columns are added directly to tables without creating multiple intermediate tables.
We can easily implement calculate columns using apply method of pandas. However, we cannot use this technique in the case of multiple tables. Prosto is intended for and makes it easy to process data stored in many tables by relying on link columns which are also evaluated from the data.
Getting rid of join and group-by¶
Column definitions such as link columns and aggregate columns are used instead of join and groupby set operations.
Data in multiple tables can be processed using the relational join operation. However, it is tedious, error prone and requires high expertise especially in the case of many tables. Prosto does not use joins. Instead, it relies on link columns which also have definitions and are evaluated during workflow execution.
Data aggregation is typically performed using some kind of group-by operation. Prosto does not use this relational operation by providing column operations for that purpose which are simpler and more natural especially in describing complex analytical workflows.
Flexibility and modularization via user-defined functions¶
UDFs describe what needs to be done with the data only in this operation using arbitrary Python code. If UDF for an operation changes then it is not necessary to update other operations.
Prosto is very flexible in defining how data will be processed because it relies on user-defined functions which are its minimal units of data processing. They provide the logic of processing at the level of individual values while the logic of looping through the sets is implemented by the system according to the type of operation applied. User-defined functions can be as simple as format conversion and as complex as as a machine learning algorithm.
Parameterization of operations by a model object¶
A model can be as simple as one value and as complex as a trained deep neural network. This feature leads to a novel view of how data analysis should be organized by combining feature engineering and machine learning so that both model training and model use (predictions or transformations) are part of one data processing workflow. Currently models are supported only as static parameters but in future there will be a possibility to train model within the same workflow
Future directions¶
- In future,
Prostowill implement such features as incremental evaluation for processing only what has changed, model training for training models as part of the workflow, data/model persistence and other data processing and analysis operations. - Data Dictionary (DD) for declaring schema, tables and columns, and Feature Store (FS) for defining operations over these data objects
References¶
[1]: A.Savinov. On the importance of functions in data modeling, Eprint: arXiv:2012.15570 [cs.DB], 2019. https://www.researchgate.net/publication/348079767_On_the_importance_of_functions_in_data_modeling
[2]: A.Savinov. Concept-oriented model: Modeling and processing data using functions, Eprint: arXiv:1606.02237 [cs.DB], 2019. https://www.researchgate.net/publication/337336089_Concept-oriented_model_Modeling_and_processing_data_using_functions
[3]: A.Savinov. From Group-By to Accumulation: Data Aggregation Revisited, Proc. IoTBDS 2017, 370-379. https://www.researchgate.net/publication/316551218_From_Group-by_to_Accumulation_Data_Aggregation_Revisited
[4]: A.Savinov. Concept-oriented model: the Functional View, Eprint: arXiv:1606.02237 [cs.DB], 2016. https://www.researchgate.net/publication/303840097_Concept-Oriented_Model_the_Functional_View
[5]: A.Savinov. Joins vs. Links or Relational Join Considered Harmful, Proc. IoTBD 2016, 362-368. https://www.researchgate.net/publication/301764816_Joins_vs_Links_or_Relational_Join_Considered_Harmful